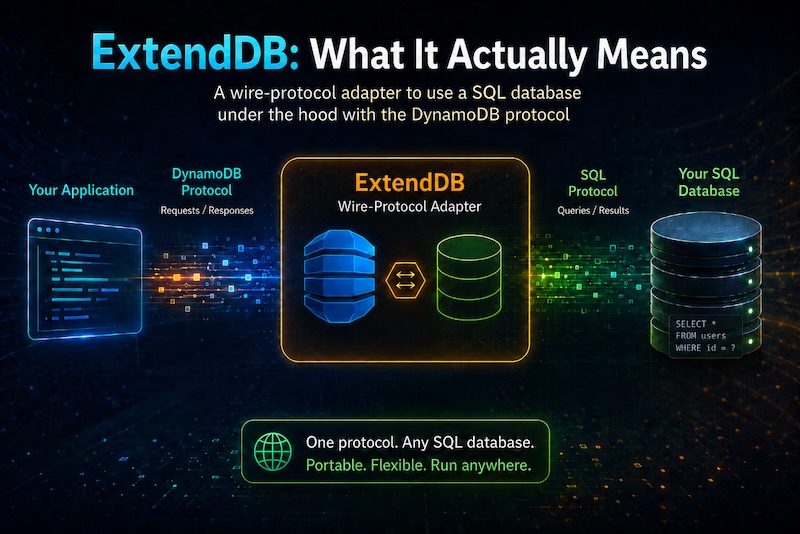
AWS just open-sourced ExtendDB, a Rust implementation of the DynamoDB wire protocol that stores data in PostgreSQL. It supports the full DynamoDB API surface — tables, items, queries, transactions, streams, TTL — and your existing AWS SDKs connect by changing only the endpoint URL. It's v0.1, Apache 2.0 licensed, and explicitly not a replacement for the managed service.
The recent announcement of ExtendDB from the DynamoDB team is one of the more surprising things AWS has published in a while. Not because the technology is groundbreaking, but because it's such a strange answer to a problem most people didn't expect AWS to solve this way. Customers wanted DynamoDB's access patterns in places they couldn't deploy DynamoDB. Instead of another managed offering, AWS open-sourced a protocol adapter and told people to bring their own storage.
The Obvious Win: DynamoDB Local Is Finally Dead
Start with the thing that matters most to anyone building on DynamoDB today.
DynamoDB Local has been the standard for local development and CI/CD testing since 2013. It's a Java process that sort-of implements the DynamoDB API. I say "sort-of" because anyone who's relied on it in a real test suite knows the pain:
- Condition expressions that pass locally and fail against the real service
- Missing features that silently succeed instead of erroring
- A single-threaded process that doesn't reflect real concurrency behavior
- No streams support worth mentioning
- Startup time that makes fast CI pipelines impossible
ExtendDB fixes all of this. It implements the wire protocol faithfully, written in Rust (so it's fast), compiles to a single binary (no JVM), and supports the full API surface including streams and transactions. Your integration tests can actually trust the results.
If ExtendDB did nothing else, this alone would make it worth adopting. Every team I've worked with that uses DynamoDB has a story about a bug that DynamoDB Local missed.
The Interesting Part: Pluggable Backends
The architecture is what makes this more than a better test tool. ExtendDB has a pluggable storage layer — you can swap in different databases behind the DynamoDB protocol. PostgreSQL is the first implementation, but the post explicitly mentions Apache Cassandra as a future option.
This is AWS saying the DynamoDB API and data modeling patterns have value independent of the managed service.
That's a philosophical shift. DynamoDB has always been a tightly coupled package: the API, the storage engine, the scaling behavior, the operational model. You couldn't separate them. If you wanted DynamoDB's access patterns, you used DynamoDB. Full stop.
Now AWS is decoupling the API from the engine. Your application speaks DynamoDB, but the storage could be PostgreSQL on your laptop, Cassandra in your data center, or the actual DynamoDB service in AWS. Same code, same SDKs, same access patterns. Different backend.
The Use Cases They're Targeting
The blog post frames three scenarios:
Local development and CI/CD. This is the immediate, practical win. Run your DynamoDB integration tests locally with zero cloud dependency. Tests start in seconds, run deterministically, and tear down cleanly.
On-premises and air-gapped environments. The airline example in the post is compelling: gate systems that need to keep working during network outages, using the same access patterns as the cloud-connected systems. Healthcare, defense, and manufacturing have similar requirements.
Multi-cloud and hybrid. This is the one AWS buries in the middle but is arguably the most significant. If your DynamoDB application can run anywhere PostgreSQL runs, you're no longer locked to AWS for every deployment target.
What This Means for Architecture Decisions
If you're evaluating DynamoDB for a new project, ExtendDB changes the risk calculus slightly:
The "vendor lock-in" objection weakens. One of the common arguments against DynamoDB is that you're locked to AWS forever. With ExtendDB, your application code and data models are portable. You'd lose the managed scaling and operational benefits of the real service, but your code works elsewhere. That's a real escape hatch, even if you never use it.
DynamoDB patterns become more attractive for edge/hybrid architectures. If you have workloads that need to run both in AWS and outside it, you previously had to maintain two data access layers. Now you can use DynamoDB patterns everywhere and swap the backend based on where the code runs.
The testing story is finally good. This might sound minor, but it's not. Teams that avoided DynamoDB because testing was painful now have a real answer. Fast, faithful local testing removes an adoption barrier that's been there since day one.
What This Does Not Change
What ExtendDB is not:
It's not DynamoDB. The performance characteristics are completely different. DynamoDB gives you single-digit millisecond latency at any scale because of how it distributes data across partitions. ExtendDB backed by PostgreSQL gives you... PostgreSQL performance. Which is fine for testing and edge scenarios, but don't expect the same behavior under load.
It doesn't replace the managed service for production cloud workloads. If you're running in AWS and need DynamoDB's scaling, availability, and operational properties, you still use DynamoDB. ExtendDB is for everywhere else.
It's v0.1. This is early. The API coverage looks comprehensive on paper, but edge cases in expression evaluation, transaction semantics, and streams behavior will take time to shake out. I wouldn't run production workloads on it today.
You're responsible for operations. DynamoDB's biggest selling point is that you never think about the database. With ExtendDB, you're running PostgreSQL (or whatever backend), which means backups, replication, monitoring, and maintenance are on you.
The Aurora Clone Angle Nobody's Talking About
Here's a use case the blog post doesn't mention that might be the most interesting one for teams already running in AWS.
DynamoDB has no concept of database cloning. If you want to test against production-like data, your options are painful: full table export to S3 and re-import (slow, expensive), point-in-time recovery to a new table (full copy at full cost, time proportional to table size), or maintaining a separate staging table you manually keep in sync. None of these give you "spin up a copy in 5 seconds, run my tests, throw it away."
Aurora PostgreSQL does. Aurora cloning uses copy-on-write at the storage layer — you get a full copy of the database in seconds regardless of size, and you only pay for pages that actually change. It's essentially free until you start writing to the clone.
Now combine the two: run ExtendDB against Aurora PostgreSQL, use Aurora's cloning to spin up isolated test environments with real production data shapes, run your DynamoDB integration tests against the clone, delete it when done. You get faithful DynamoDB API behavior and instant database snapshots for testing — something you literally cannot do with DynamoDB itself.
For teams with large DynamoDB tables where reproducing production data patterns in test environments is a constant headache, this architecture actually solves the problem. It's not cheap (you're paying for Aurora plus an ExtendDB compute layer), but it solves a problem that DynamoDB has no native answer for.
Is it a Rube Goldberg machine? A little. But if your test suite needs to validate behavior against realistic data volumes and you're tired of maintaining hand-crafted test fixtures, it might be worth the complexity.
What I'd Do With It Today
If I were adopting ExtendDB right now, here's where I'd start:
-
Replace DynamoDB Local in CI/CD pipelines. Easiest win. Your integration tests get faster and more reliable immediately.
-
Use it for local development. Spin it up alongside your application, run against it during development, deploy against real DynamoDB. The endpoint URL is the only difference.
-
Explore the Aurora clone pattern for integration testing. If you have large tables and need to test against realistic data, ExtendDB on Aurora with cloning gives you something DynamoDB can't.
-
Wait on production edge/on-premises use cases. It's too early. Let the project mature, let the community find the bugs, and revisit in 6 months.
-
Watch the Cassandra backend. If they ship a Cassandra storage adapter, that opens up horizontally-scaled DynamoDB-compatible deployments outside AWS. That's a much bigger deal than PostgreSQL for production use cases.
For FluentDynamoDB Users
If you're using FluentDynamoDB (my open-source DynamoDB client library), ExtendDB works out of the box. FluentDynamoDB uses the standard AWS SDK under the hood, so you configure the endpoint URL and everything else stays the same. This makes it trivial to run your FluentDynamoDB-based repositories against ExtendDB in tests.
I'll be adding ExtendDB to FluentDynamoDB's CI pipeline as a more faithful test backend. If you're doing the same, the only configuration change is:
var client = new AmazonDynamoDBClient(new AmazonDynamoDBConfig
{
ServiceURL = "https://127.0.0.1:8000"
});
Same as DynamoDB Local, but now the tests actually mean something.
The Bottom Line
ExtendDB is a better DynamoDB Local today, and potentially something much more interesting tomorrow. The pluggable backend architecture and the fact that it's open source (not just source-available) suggest AWS has bigger plans for this than just fixing local testing.
For teams already on DynamoDB, adopt it for testing immediately. For teams evaluating DynamoDB, the portability story is now much stronger. For teams running hybrid or edge workloads, keep watching — this could be exactly what you need in 6-12 months.
The DynamoDB API is becoming a standard, not just a service.
